

1. CollabSim: A CSCW-Grounded Methodology for Investigating Collaborative Competence of LLM Agents through Controlled Multi-Agent Experiments
Jiaju Chen, Bo Sun, Yuxuan Lu, Yun Wang, Dakuo Wang, Bingsheng Yao

2. Do More Agents Help? Controlled and Protocol-Aligned Evaluation of LLM Agent Workflows
Yuhang Fu, Ruishan Fang, Jiaqi Shao, Huiyu Zheng, Zhengtao Zhu, Bing Luo, Tao Lin

3. Agent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads
Yasmine Omri, Ziyu Gan, Zachary Broveak, Robin Geens, Zexue He, Alex Pentland, Marian Verhelst, Tsachy Weissman, Thierry Tambe

4. Beyond tokens: a unified framework for latent communication in LLM-based multi-agent systems

5. EGTR-Review: Efficient Evidence-Grounded Scientific Peer Review Generation via Multi-Agent Teacher Distillation
Xinpeng Qiu, Wang Yihu, Zhifeng Liu, Xiaochen Wang, Jimin Wang

6. Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
Chenming Zhu, Jingli Lin, Yilin Long, Peizhou Cao, Tai Wang, Jiangmiao Pang, Xihui Liu

7. From Reward-Hack Activations to Agentic Risk States: Context-Calibrated Mechanistic Monitoring in LLM Agents

8. Harnessing Generalist Agents for Contextualized Time Series
Zihao Li, Kaifeng Jin, Yuanchen Bei, Jiaru Zou, Avaneesh Kumar, ..., Yanjun Zhao, Mengting Ai, Baoyu Jing, Hanghang Tong, Jingrui He

9. Humans' ALMANAC: A Human Collaboration Dataset of Action-Level Mental Model Annotations for Agent Collaboration
Jiaju Chen, Yuxuan Lu, Jiayi Su, Chaoran Chen, Songlin Xiao, ..., Jian Zhao, Tongshuang Wu, Toby Jia-Jun Li, Dakuo Wang, Bingsheng Yao

10. AURA: Intent-Directed Probing for Implicit-Need Surfacing in Situated LLM Agents
Yang Li, Jiaxiang Liu, Jiang Cai, Mingkun Xu
Show 86 more

11. Critic-Guided Heterogeneous Multi-Agent Reasoning for Reliable Mathematical Problem Solving
Muhammad Talha Sharif, Abdul Rehman

12. From Risk Classification to Action Plan Remediation: A Guardrail Feedback Driven Framework for LLM Agents
Yuhao Sun, Jiacheng Zhang, Shaanan Cohney, Zhexin Zhang, Feng Liu, Xingliang Yuan

13. When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Dongsheng Zhu, Xuchen Ma, Yucheng Shen, Xiang Li, Yukun Zhao, Shuaiqiang Wang, Lingyong Yan, Dawei Yin

14. Beyond Similarity: Trustworthy Memory Search for Personal AI Agents
Jiawen Zhang, Kejia Chen, Jiachen Ma, Yangfan Hu, Lipeng He, Yechao Zhang, Jian Liu, Xiaohu Yang, Tianwei Zhang, Ruoxi Jia

15. ToolChoiceConfusion: Causal Minimal Tool Filtering for Reliable LLM Agents
Rahul Suresh Babu, Laxmipriya Ganesh Iyer


17. SHIELDS: Automating OS Hardening with Iterative Multi-Agent Remediation
Andrew Hamara, Dwight Horne, Aldehir Rojas, Timothy Kurniawan, Sophie Lamothe, Vishal Suresh, Nicholas Turoci, Lawrence Wong

18. The Self-Correction Illusion: LLMs Correct Others but Not Themselves
Kuan-Yen Chen, Fang-Yi Su, Jung-Hsien Chiang

19. Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents

20. Unsupervised Skill Discovery for Agentic Data Analysis
Zhisong Qiu, Kangqi Song, Shengwei Tang, Shuofei Qiao, Lei Liang, Huajun Chen, Shumin Deng

21. CollabBench: Benchmarking and Unleashing Collaborative Ability of LLMs with Diverse Players via Proactive Engagement
Hong Qian, Yuanhao Liu, Zihan Zhou, Zongbao Zhang, Hanjie Ge, Haotian Shi, Liang Dou, Xiangfeng Wang, Jingwen Yang, Aimin Zhou

22. Agent-Orchestrated Adaptive RAG: A Comparative Study on Structured and Multi-Hop Retrieval
Anuj Maharjan, Devinder Kaur, Richard Molyet

23. Benchmark Everything Everywhere All at Once
Shiyun Xiong, Dongming Wu, Peiwen Sun, Yuang Ai, Bokang Yang, Wencheng Han, Xiao-Hui Li, Xiangyu Yue

24. Policy-Conditioned Counterfactual Credit for Verifiable Reinforcement Learning of Long-Horizon Language Agents

25. AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Jiayu Liu, Cheng Qian, Zhenhailong Wang, Bingxuan Li, Jiateng Liu, ..., Jeonghwan Kim, Yumeng Wang, Xiusi Chen, Yi R. Fung, Heng Ji

26. What Should Agents Say? Action-state Communication for Efficient Multi-Agent Systems
Chen Huang, Yuhao Wu, Wenxuan Zhang

27. Ten Headache Specialists versus Artificial Intelligence for Clinical Literature Summarization: A Critical Evaluation and Comparison
Alejandro Lozano, Keiko Ihara, Ping-Hao Yang, Carrie E. Robertson, Jennifer Stern, ..., Fred Cohen, Todd J. Schwedt, Jenelle A. Jindal, Serena Yeung-Levy, Chia-Chun Chiang


29. ProSPy: A Profiling-Driven SQL-Python Agentic Framework for Enterprise Text-to-SQL
Zhaorui Yang, Huawei Zheng, Sen Yang, Yuhui Zhang, Haoxuan Li, ..., Haozhe Feng, Danqing Huang, Yingcai Wu, Peng Chen, Wei Chen

30. Latent Reasoning with Normalizing Flows
Guancheng Tu, Xiangjun Fu, Suhao Yu, Yao Tang, Haoqiang Kang, Lianhui Qin, Yizhe Zhang, Jiatao Gu

31. Domain-Conditioned Safety in Frontier Computer-Using Agents: A 793-Episode Browser Benchmark, a Coding-Domain Cross-Reference, and a Reproducibility Audit of Recent Red-Teaming

32. DexFuture: Hierarchical Future-State Visuomotor Targeting for Bimanual Dexterous Tool Use
Runfa Blark Li, Kuang-Ting Tu, Nikola Raicevic, Dwait Bhatt, Xinshuang Liu, Keito Suzuki, Ki Myung Brian Lee, Nikolay Atanasov, Truong Nguyen

33. AdaMEM: Test-Time Adaptive Memory for Language Agents
Yunxiang Zhang, Yiheng Li, Ali Payani, Lu Wang

34. MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
Shangheng Du, Xiangchao Yan, Jinxin Shi, Zongsheng Cao, Shiyang Feng, ..., Xin Li, Jie Zhou, Liang He, Bo Zhang, Lei Bai

35. When Evidence is Sparse: Weakly Supervised Early Failure Alerting in Dialogs and LLM-Agent Trajectories
Avinash Baidya, Xinran Liang, Ruocheng Guo, Xiang Gao, Kamalika Das

36. PlanBench-V: A Spatial Planning Map Benchmark for Vision-Language Models
Minxin Chen, He Zhu, Junyou Su, Wen Wang, Yijie Deng, Wenjia Zhang

37. MARDoc: A Memory-Aware Refinement Agent Framework for Multimodal Long Document QA
Kaifeng Chen, Hongtao Liu, Qiyao Peng, Jian Yang, Yongqiang Liu, Xiaochen Zhang, Qing Yang

38. Reducing Hallucinations in Complex Question Answering using Simple Graph-based Retrieval-Augmented Generation (long version)
Christopher J. Wedge, Joshua Stutter, Danny Dixon, Jacek Cała

39. Global-Local Monte Carlo Tree Search in Vision-Language Models for Text-to-3D Indoor Scene Generation
Mengshi Qi, Wei Deng, Xianlin Zhang, Huadong Ma

40. StoryVideoQA: Scaling Deep Video Understanding with a Large-Scale, Multi-Genre and Auto-Generated Dataset
Zhengqian Wu, Zhixian Liu, Aodong Chen, Jingyang Zhang, Ruizhe Li, Hanlin Ge, Zhongyuan Wang, Chunxia Xiao, Chao Liang

41. Merging model-based control with multi-agent reinforcement learning for multi-agent cooperative teaming strategies
Christian Llanes, Spencer W. Jensen, Samuel Coogan

42. How Far Did They Go? The Persuasive Tactics of Covert LLM Agents in a Discontinued Field Experiment

43. Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
Wenbo Pan, Shujie Liu, Chin-Yew Lin, Jingying Zeng, Xianfeng Tang, Xiangyang Zhou, Yan Lu, Xiaohua Jia
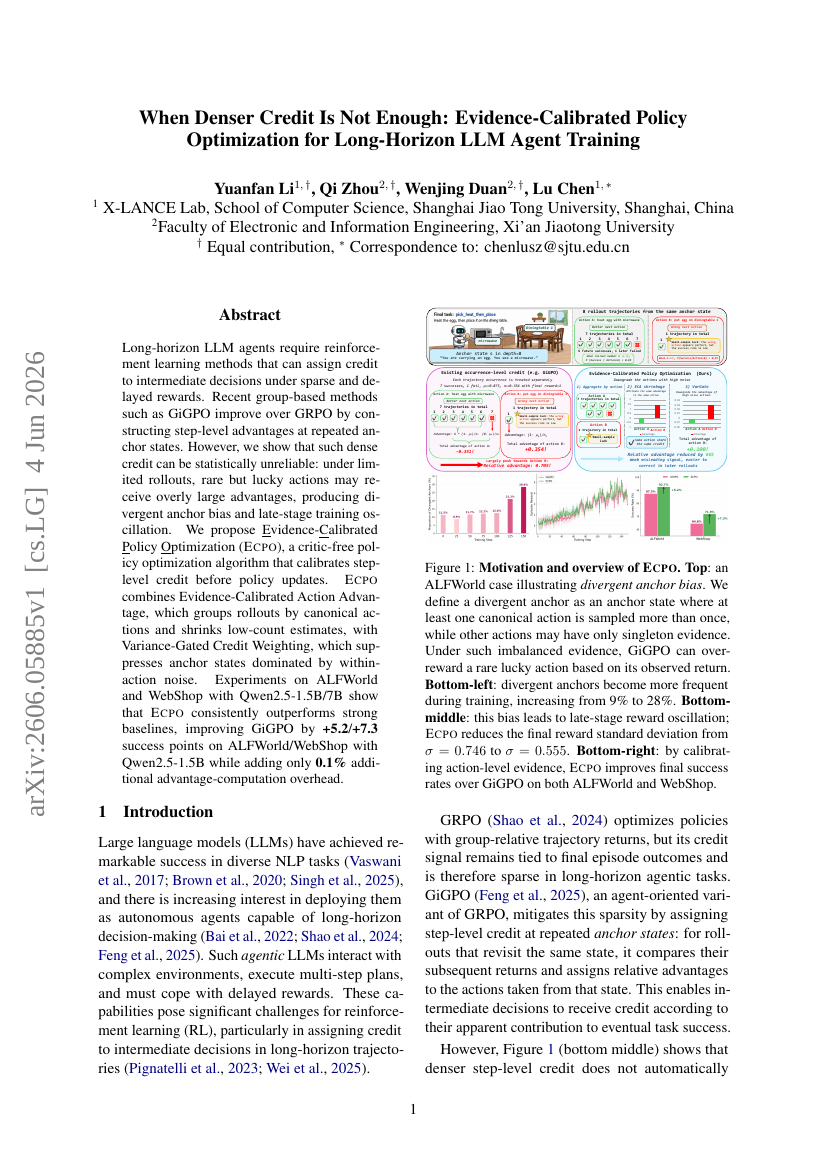
44. When Denser Credit Is Not Enough: Evidence-Calibrated Policy Optimization for Long-Horizon LLM Agent Training
Yuanfan Li, Qi Zhou, Wenjing Duan, Lu Chen

45. ReasoningFlow: Discourse Structures for Understanding LLM Reasoning Traces
Jinu Lee, Shivam Agarwal, Amruta Parulekar, Siddarth Madala, Dilek Hakkani-Tur, Julia Hockenmaier

46. LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Aofan Yu, Chenyu Zhou, Tianyi Xu, Zihan Guo, Rong Shan, ..., Jun Wang, Weiwen Liu, Yong Yu, Weinan Zhang, Jianghao Lin

47. Membrane: A Self-Evolving Contrastive Safety Memory for LLM Agent Defense
Minseok Choi, Seungbin Yang, Dongjin Kim, Subin Kim, Jungmin Son, Yunseung Lee, Jaegul Choo, Youngjun Kwak

48. RedEdit: Agentic Red-Teaming of Image Safety Classifiers via MCTS-Guided Photo-Editing
Weilin Lin, Ziqi Lin, Zhenxing Zhou, Jianze Li, Tong Zhang, Hui Xiong, Li Liu

49. Brick-Composer: Using MLLMs for Assembly with Diverse Bricks
Jiateng Liu, Bingxuan Li, Zhenhailong Wang, Rushi Wang, Kaiwen Hong, ..., Jiayu Liu, Denghui Zhang, Katherine Driggs-Campbell, Manling Li, Heng Ji

50. LeanMarathon: Toward Reliable AI Co-Mathematicians through Long-Horizon Lean Autoformalization
Yuanhe Zhang, Yuekai Sun, Taiji Suzuki, Jason D. Lee, Fanghui Liu

51. PSEBench: A Controllable and Verifiable Benchmark for Evaluating LLMs in Patient Safety Event Triage
Keqi Han, Ryan Young, Annabel Strauss, Lindsey Hughes, Katharine M. Nesbitt, Nicole Schueler, Che Ngufor, Carl Yang, Yuan Xue, Zhijun Yin

52. SciVisAgentSkills: Design and Evaluation of Agent Skills for Scientific Data Analysis and Visualization
Kuangshi Ai, Haichao Miao, Kaiyuan Tang, Shusen Liu, Chaoli Wang

53. PerceptUI: LLM Agents as Human-Aligned Synthetic Users for UI/UX Evaluation
Nicolas Bougie, Xiaotong Ye, Gian Maria Marconi, Narimasa Watanabe

54. TAPO: Tool-Aware Policy Optimization via Credit Transfer for Multimodal Search Agents
Chengqi Dong, Chuhuai Yue, Hang He, yandong liu, Fenghe Tang, S Kevin Zhou, Xiaohan Wang, Jiajun Chai, Guojun Yin


56. State commitment learning: training language models to distinguish computation from memory
Fei Ding, Yongkang Zhang, Runhao Liu, Yuhao Liao, Zijian Zeng, Huiming Yang

57. Autoregressive Diffusion World Models for Off-Policy Evaluation of LLM Agents
Kaixuan Liu, Guojun Xiong, Weinan Zhang, Shengpu Tang


59. RREDCoT: Segment-Level Reward Redistribution for Reasoning Models
Mykyta Ielanskyi, Kajetan Schweighofer, Lukas Aichberger, Sepp Hochreiter

60. LoRi: Low-Rank Distillation for Implicit Reasoning
Ryan Solgi, Jiayi Tian, Zheng Zhang


62. TARPO: Token-Wise Latent-Explicit Reasoning via Action-Routing Policy Optimization
Liting Zhang, Shiwan Zhao, Xuyang Zhao, Zichen Xu, Jianye Wang, Qicheng Li

63. Beyond Alignment: Value Diversity as a Collective Property in Multicultural Agent Systems
Shaoyang Xu, Jingshen Zhang, Long P. Hoang, Jinyuan Li, Wenxuan Zhang

64. Emergent Language as an Approach to Conscious AI

65. ZERO-APT: A Closed-Loop Adversarial Framework for LLM-Driven Automated Penetration Testing under Intelligent Defense

66. GenTI: Benchmarking LLMs for Autonomous IDPS Rule Generation for Unseen Attacks
Hassan Jalil Hadi, Rehana Yasmin, Ali Shoker

67. WebMCP Tool Surface Poisoning: Runtime Manipulation Attacks on LLM Agents
Lin-Fa Lee, Yi-Yu Chang, Chia-Mu Yu, Kuo-Hui Yeh

68. Will the Agent Recuse Itself? Measuring LLM-Agent Compliance with In-Band Access-Deny Signals

69. VTI-CoT: Visual-Textual Interleaved Chain of Thought for Video Reasoning
Shufan Zhang, Ziyue Lin, Bairun Wang, Lei Jin, Xuanding Ding, Xinzhu Ma, Kunlin Yang

70. Beyond Absolute Scores: Relative Edit-induced Difference for Generalizable Image Aesthetic Assessment
Qifei Jia, Xintong Yao, Minghao Li, Yajie Chai, Qiming Lu, Baoyue Shen, Yasen Zhang, Runyu Shi, Ying Huang, Yue Zhang

71. ANCHOR: Agentic Noise Creation Framework for Human Simulation and Denoising Recommendation
Xiangming Li, Hua Chu, Chengyu Feng, Jianan Li, Yangtao Zhou

72. OneReason Technical Report
OneRec Team, Biao Yang, Boyang Ding, Chenglong Chu, Dunju Zang, ..., Zhaojie Liu, Zhiyang Zhang, Zhuang Zhuang, Ziqi Wang, Ziyi Zhao

73. Dynamic Multi-Agent Pickup and Delivery in Robotic Cellular Warehousing Systems
Cheng Ren, Ming Li, Xinping Guan, George Q. Huang

74. Learning of Robot Safety Policies via Adversarial Synthetic Scenarios
Nikolai Dorofeev, Alexey Odinokov, Rostislav Yavorskiy

75. RiskFlow: Fast and Faithful Safety-Critical Traffic Scenario Generation
Qi Lan, Yining Tang, Yu Shen, Yi Zhou, Yuhao Wei, Jie Li, Guofa Li

76. Flow-based Policy Adaptation without Policy Updates
Luzhe Sun, Jingtian Ji, Haoran Chen, Jiawei Zhou, Matthew R. Walter

77. HANDOFF: Humanoid Agentic Task-Space Whole-Body Control via Distilled Complementary Teachers
Lizhi Yang, Junheng Li, Nehar Poddar, Yiling Hou, Gio Huh, Robert Griffin, Georgia Gkioxari, Aaron Ames

78. SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
Taewon Yun, Hyeonseong Park, Jeonghwan Choi, Hayoon Park, Yeeun Choi, Hwanjun Song

79. Agentic Molecular Recovery via Molecule-Aware Exploration

80. Evaluating Agentic Configuration Repair for Computer Networks
Rufat Asadli, Benjamin Hoffman, Ioannis Protogeros, Laurent Vanbever

81. An Infectious Disease Spread Simulation Based on Large Language Model Decision Making
Yonchanok Khaokaew, Ruochen Kong, Andreas Zufle, Hao Xue, Taylor Anderson, Chandini Raina MacIntyre, Matthew Scotch, Flora D. Salim, David J Heslop

82. Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jui-Hui Chung, Ziyang Cai, Zihao Li, Qishuo Yin, Rohit Agarwal, ..., Mengdi Wang, Danqi Chen, Chi Jin, Liam H Fowl, Sanjeev Arora


84. VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
Lin Fu, Zheyuan Yang, Yang Wang, Tingyu Song, Arman Cohan, Yilun Zhao

85. Self-Commitment Latency: A Reward-Free Probe for Prompted Implicit Hacking
Bonan Shen, Youting Wang, Dingyan Shang, Tao Ning

86. Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
Maxime Griot, Paul Steven Scotti, Tanishq Mathew Abraham


88. ShotCrop$^3$: Cropping Human-Centric Images into Cinematic Triple-Shot Compositions
Dehong Kong, Lina Lei, Lingtao Zheng, Chenyang Wu, Ailing Zhang, ..., Zhixin Wang, Zhikai Chen, Xuecheng Qi, Renjing Pei, Fan Li

89. DisasterBench: A Multimodal Benchmark for UAV-Based Disaster Response in Complex Environments
Tan Zhang, Quanyou Li, Lu Zhang, Jun Liu, Xiaofeng Zhu, Ping Hu

90. Towards One-to-Many Temporal Grounding
Qi Xu, Yue Tan, Shihao Chen, Jiahao Meng, Anna Wang, Shunping Ji, Hao Fei, Jason Li


92. MPCoT: Reward-Guided Multi-Path Latent Reasoning for Test-Time Scalable Vision-Language-Action

93. The Granularity Gap: A Multi-Dimensional Longitudinal Audit of Sycophancy in Gemini Models

94. From Self to Other: Evaluating Demographic Perspective-Taking in LLM Hate Speech Annotation


96. BMCR: Adaptive Backbone Module Composition via Reinforcement Learning for Remote Sensing Object Detection
Wenlin Liu, Xikun Hu, Ping Zhong