

1. Less Context, Better Agents: Efficient Context Engineering for Long-Horizon Tool-Using LLM Agents
Abhilasha Lodha, Mahsa Pahlavikhah Varnosfaderani, Abir Chakraborty, Abhinav Mithal


3. Pushing the Limits of LLM Tool Calling via Experiential Knowledge Integration and Activation
Yupu Hao, Zhuoran Jin, Huanxuan Liao, Kang Liu, Jun Zhao

4. Toward Secure LLM Agents: Threat Surfaces, Attacks, Defenses, and Evaluation
Yuchen Ling, Shengcheng Yu, Zhenyu Chen, Chunrong Fang

5. Assessing Automated Prompt Injection Attacks in Agentic Environments
David Hofer, Edoardo Debenedetti, Florian Tramèr

6. Divide and Cooperate: Role-Decomposed Multi-Agent LLM Training with Cross-Agent Learning Signals
Jaewan Park, Solbee Cho, Jay-Yoon Lee

7. ABC-Bench: An Agentic Bio-Capabilities Benchmark for Biosecurity
Andrew Bo Liu, Samira Nedungadi, Bryce Cai, Alex Kleinman, Harmon Bhasin, Seth Donoughe

8. MIRAGE: A Polarity-Flipping Encoding Subspace in LLM Agents
Pratibha Revankar, Kargi Chauhan, Jihye Kim, Sadiba Nusrat Nur, Vincent Siu, Chenguang Wang

9. WebChallenger: A Reliable and Efficient Generalist Web Agent
Jayoo Hwang, Xiaowen Zhang, Vedant Padwal

10. T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains
Genta Indra Winata, Amartya Chakraborty, Yuzhen Lin, Swasthi P Rao, Shikhhar Siingh, ..., Kshitij Tayal, Xiuzhu Lin, Anirban Das, Sambit Sahu, Shi-Xiong Zhang
Show 53 more


12. AgenticNav: Zero-Shot Vision-and-Language Navigation as a Tool-Calling Harness
Yijian Li, Changze Li, Hantian Shi, Jiaying Luo, Jiyuan Cai, Ming Yang, Tong Qin

13. Mind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?
Tengchao Lv, Dongdong Zhang, Jiayu Ding, Yilin Jia, Yuzhong Zhao, ..., Shaohan Huang, Nan Yang, Li Dong, Lei Cui, Furu Wei

14. TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
Heming Zou, Qi Wang, Yun Qu, Yuhang Jiang, Lizhou Cai, ..., Xin Xu, Weijie Liu, Kai Yang, Saiyong Yang, Xiangyang Ji

15. The Shibboleth Effect: Auditing the Cross-Lingual Distributional Skew of Large Language Models

16. Infini Memory: Maintainable Topic Documents for Long-Term LLM Agent Memory
Suozhao Ji, Baodong Wu, Zehao Wang, Lei Xia, Qingping Li, ..., Wenbo Ding, Zhenhua Zhu, Boxun Li, Guohao Dai, Yu Wang

17. AutoPDE: Reliable Agentic PDE Solving via Explicitly Represented Solver Strategies
Huanshuo Dong, Keyao Zhang, Hong Wang, Zhezheng Hao, Zhiwei Zhuang, Ziyan Liu, Jiacong Wang, Gengyuan Liu, Xin Jin

18. 3SPO: State-Score-Supervised Policy Optimization for LLM Agents
Yu Han, Kailing Li, Yang Jiao, Yulin Dai, Yuqian Fu, Linhai Zhuo, Tianwen Qian

19. TabClaw: An Interactive and Self-Evolving Agent for Spreadsheet Manipulation and Table Reasoning
Mingyue Cheng, Shuo Yu, Daoyu Wang, Qingchuan Li, Xiaoyu Tao, Qingyang Mao, Yitong Zhou, Qi Liu
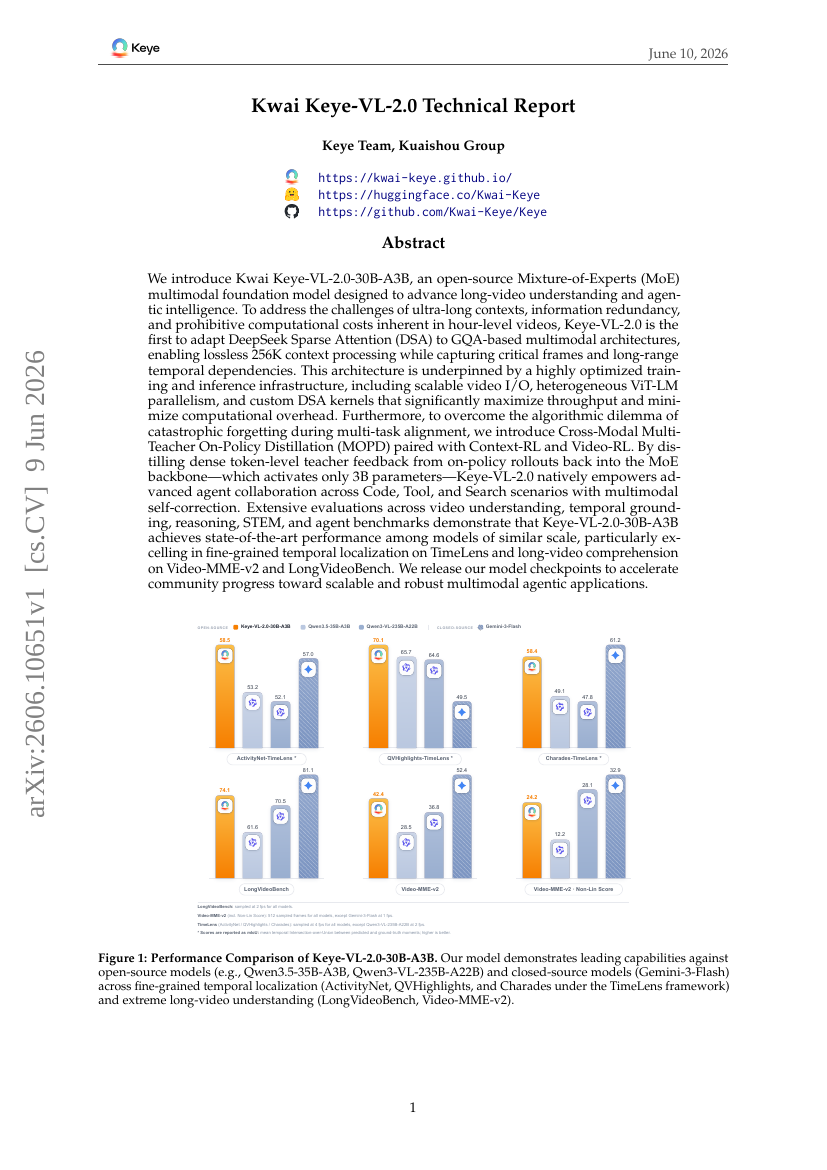
20. Kwai Keye-VL-2.0 Technical Report
Kwai Keye Team, Bin Wen, Changyi Liu, Chengru Song, Chongling Rao, ..., Jing Wang, Jinghui Jia, Junmin Chen, Junyu Shi, Ruilin Zhang
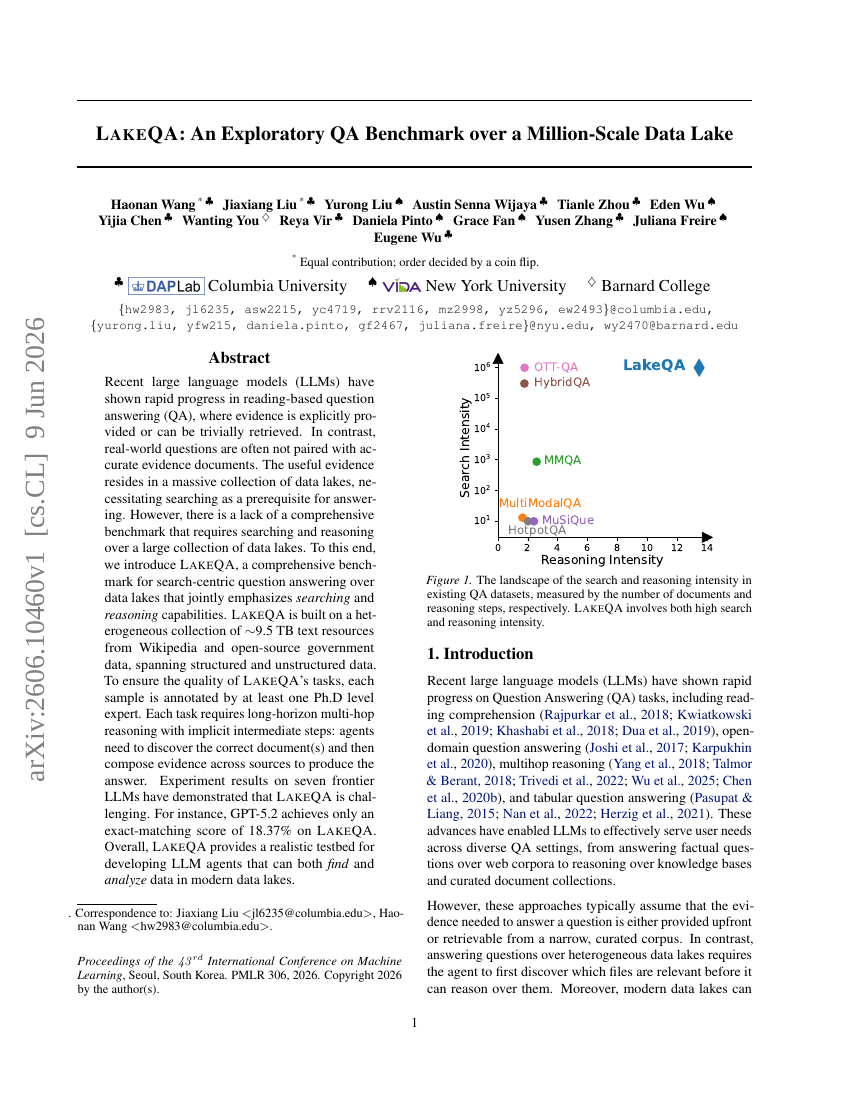
21. LakeQA: An Exploratory QA Benchmark over a Million-Scale Data Lake
Haonan Wang, Jiaxiang Liu, Yurong Liu, Austin Senna Wijaya, Tianle Zhou, ..., Daniela Pinto, Grace Fan, Yusen Zhang, Juliana Freire, Eugene Wu

22. Trace Only What You Need: Structure-Aware On-Demand Hypergraph Memory for Long-Document Question Answering
Xiangjun Zai, Xingyu Tan, Chen Chen, Xiaoyang Wang, Wenjie Zhang

23. IntentKV: Cross-Turn Intent-Aware KV Cache Pruning for Agent Inference

24. Monte Carlo Pass Search: Using Trajectory Generation for 3D Counterfactual Pass Evaluation in Football

25. ReasonAlloc: Hierarchical Decoding-Time KV Cache Budget Allocation for Reasoning Models
Wenhao Liu, Hao Shi, Yunhe Li, Weizhi Fei, Xiangyuan Wang, Mengzhe Ruan, Hanxu Hou, Peisong Wang, Linqi Song, Shuang Qiu

26. Attention Amnesia in Hybrid LLMs: When CoT Fine-Tuning Breaks Long-Range Recall, and How to Fix It
Xinyu Zhou, Boyu Zhu, Yi Xu, Zhiwei Li, Yingfa Chen, Huiming Wang, Zhijiang Guo

27. Data Journalist Agent: Transforming Data into Verifiable Multimodal Stories
Kevin Qinghong Lin, Batu EI, Yuhong Shi, Pan Lu, Philip Torr, James Zou
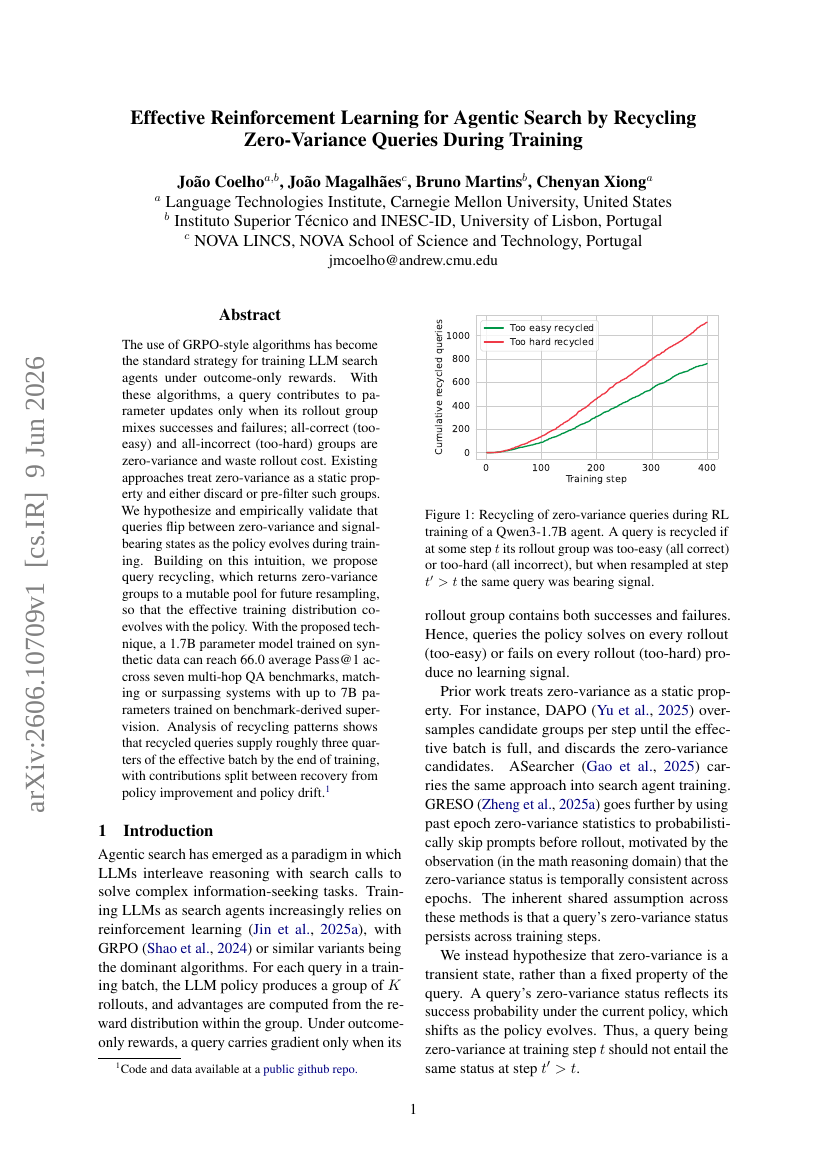
28. Effective Reinforcement Learning for Agentic Search by Recycling Zero-Variance Queries During Training
João Coelho, João Magalhães, Bruno Martins, Chenyan Xiong

29. The Arbiter Agent: Continually Monitoring Multi-Agent Conversations to Detect Emergent Misalignment
Filippo Tonini, Federico Torrielli, Anton Danholt Lautrup, Peter Schneider-Kamp, Mustafa Mert Çelikok, Lukas Galke Poech

30. Evaluating Research-Level Math Proofs via Strict Step-Level Verification

31. Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Xucong Wang, Ziyu Ma, Shidong Yang, Tongwen Huang, Pengkun Wang, Yong Wang, Xiangxiang Chu

32. A History-Aware Visually Grounded Critic for Computer Use Agents
Jaewoo Lee, Zaid Khan, Archiki Prasad, Justin Chih-Yao Chen, Supriyo Chakraborty, Kartik Balasubramaniam, Sambit Sahu, Elias Stengel-Eskin, Hyunji Lee, Mohit Bansal

33. PreAct-Bench: Benchmarking Predictive Monitoring in LLMs
Hainiu Xu, Italo Luis da Silva, Jiangnan Ye, Yuhao Wang, Wei Liu, Linyi Yang, Jonathan Richard Schwarz, Nicola Paoletti, Yulan He, Hanqi Yan


35. The Confident Liar: Diagnosing Multi-Agent Debate with Log-Probabilities and LLM-as-Judge
Ali Keramati, Justin Cheok, Jacob Horne, Mark Warschauer

36. Early-Token Confidence Predicts Reasoning Quality in Multi-Agent LLM Debate
Ali Keramati, Justin Cheok, Jacob Horne, Mark Warschauer

37. Semantic Multi-Agent Intrusion Detection for IoT:Zero-Day and Adversarial Threats with Risk-Aware Reasoning

38. MemVenom: Triggered Poisoning of Multimodal Memories in Web Agents
Yv Zhang, Hao Sun, Hao Fang, Kuofeng Gao, Fan Mo, Bin Chen, Shu-Tao Xia, Yaowei Wang

39. $τ$-Rec: A Verifiable Benchmark for Agentic Recommender Systems
Bharath Sivaram Narasimhan, Karthik R Narasimhan

40. READER: Robust Evidence-based Authorship Decoding via Extracted Representations
Jiaxu Liu, Sunnan Mu, Dong Huang, Liuyin Wang, Jing Shao, Jie Zhang

41. When RL Fails after SFT: Rejuvenating Model Plasticity for Robust SFT-to-RL Handoff
Runze Liu, Jiashun Liu, Xu Wan, Yuqian Fu, Ling Pan
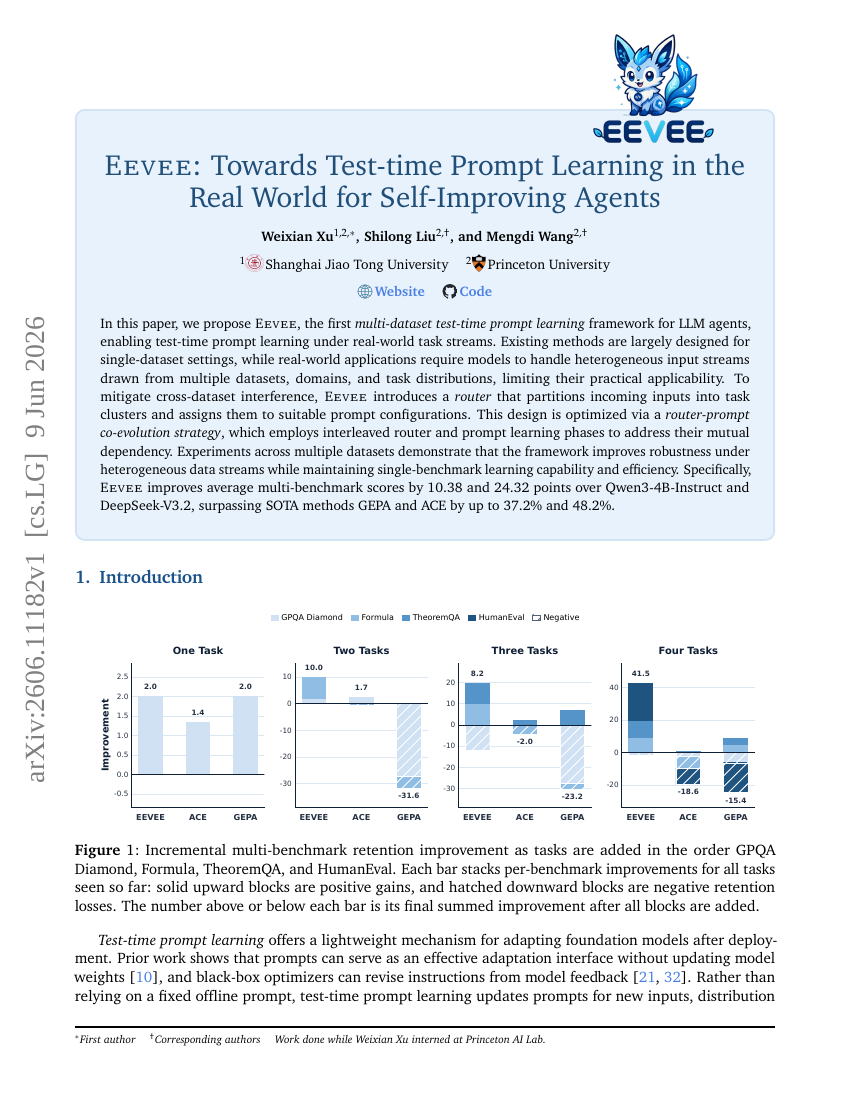
42. EEVEE: Towards Test-time Prompt Learning in the Real World for Self-Improving Agents
Weixian Xu, Shilong Liu, Mengdi Wang

43. CoCoSI: Collaborative Cognitive Map Construction for Spatial Intelligence
Yiming Zhang, Ruoxuan Cao, Zhihang Zhong

44. Sim2Schedule: A Simulator-Guided LLM Framework for Autonomous Open-Pit Mine Scheduling
Mustavi Ibne Masum, Thiago Eustaquio Alves de Oliveira, Mahzabeen Emu
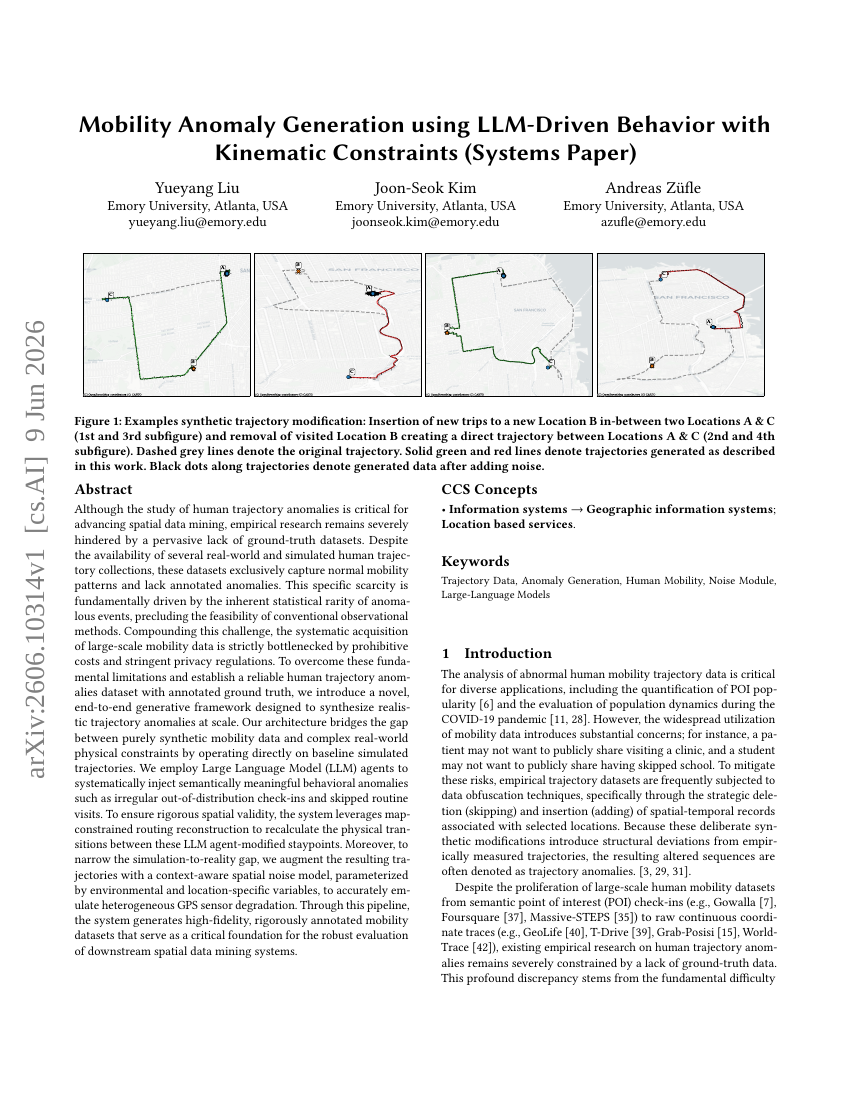
45. Mobility Anomaly Generation using LLM-Driven Behavior with Kinematic Constraints
Yueyang Liu, Joon-Seok Kim, Andreas Züfle

46. Beyond Static Evaluation: Co-Evolutionary Mechanisms for LLM-Driven Strategy Evolution in Adversarial Games
Haoran Li, Zengle Ge, Ziyang Zhang, Xiaomin Yuan, Yui Lo, ..., Jiaqun Liu, Annan Li, Jianmin Wu, Dawei Yin, Dou Shen

47. When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
Sai Kartheek Reddy Kasu, Nils Lukas, Samuele Poppi

48. Moonshine: An Autonomous Mathematical Research Agent Centered on Conjecture Generation

49. Frontier Coding Agents Use Metaprogramming to Adapt to Unfamiliar Programming Languages
Aman Sharma, Sushrut Thorat, Paras Chopra

50. Workflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
Liya Zhu, Jingzhe Ding, Jian Zhang, Jianbo Xue, Shihao Liang, ..., Shen Yan, Yujia Qin, Wenhao Huang, Zaiyuan Wang, Xiaolong Chang

51. From Confident Closing to Silent Failure: Characterizing False Success in LLM Agents

52. Can Multi-Agent LLMs Identify Their Peers? Stylometric Fingerprinting in Role-Constrained Political Analysis

53. Less Context, More Accuracy: A Bi-Temporal Memory Engine for LLM Agents Where a Lean Retrieved Context Beats the Full History

54. Harnessing the Collective Intelligence of AI Agents in the Wild for New Discoveries
Federico Bianchi, Yongchan Kwon, Aneesh Pappu, James Zou

55. Dep-LLM: Training-Free Depression Diagnosis via Evidence-Guided Structured Multi-factor with Reliable LLM Reasoning
Yiqing Lyu, Xianbing Zhao, Buzhou Tang, Ronghuan Jiang

56. Beyond APIs: Probing the Limits of MLLMs in Physical Tool Use
Zhixin Ma, Yutong Zhou, Yongqi Li, Chong-Wah Ngo, Wenjie Li

57. VISTA: A Versatile Interactive User Simulation Toolkit for Agent Evaluation
Yunan Lu, Ryan Shea, Yusen Zhang, Zhou Yu

58. GaussTrace: Provenance Analysis of 3D Gaussian Splatting Models with Evidence-based LLM Reasoning
Haoliang Han, Ziyuan Luo, Renjie Wan


60. Belief-Space Control for Personalized Cancer Treatment via Active Inference
Deniz Sargun, H. Bugra Tulay, C. Emre Koksal

61. A complementary study on PlanGPT: Evaluation with defined Performance Metrics and comparison with a planner
Youssef Abdelkader, Humbert Fiorino, Damien Pellier

62. Dropout-GRPO: Variational Stochasticity for Continuous Latent Reasoning

63. Act on What You See: Unlocking Safe Social Navigation in Vision-Language-Action Models
Qingzi Wang, Xiyang Wu, Guangyao Shi, Dianwei Chen, Xianfeng Yang, Dinesh Manocha